고정 헤더 영역
상세 컨텐츠
본문
여기서 가장 많이 사용할 라이브러리는 pandas 라는 라이브러리입니다.
pandas는 데이터 분석에서 유용하게 사용할 수 있습니다.
데이터를 보기 좋게 표로 만들어서 출력,검색, 열 붙이기 등이 가장 대표적이예요.


사용 방법도 간단해요.
첫번째 padnas 설치부터 진행합니다.
# pandas와 numpy 설치
# numpy는 대규모 다차원을 연산 수행 지원
# 다차원 = [number][number] 이상
!pip install pandas numpy그리고 사용할 꺼라고 선언해주면 돼요.
# 선언하고 나서 as 이름을 선언해주면 변수명처럼
# as 뒤에 입력한 이름으로 라이브러리를 사용 가능
import pandas as pd
import numpy as np이제 pandast를 사용하기 위해 코드를 작성해 볼께요.

data = {
'name': ['영수','철수','영희','소희'],
'age': [20,15,38,8]
}
# DataFame, 즉 틀(테이블)을 만드는데 가져올 데이터는 ()안에 입력
df = pd.DataFrame(data)
# 이제 출력하면 위에처럼 값이 출력
dfDataFrame을 사용하면 '딕셔너리 형태로 된 데이터를 표(테이블)형태로 바꿔주는 역활을 해요.

DataFrame에 추가하기
표에 행(▶)을 추가하기 원하면 append함수를 사용하여 추가할수 있어요
# 딕셔너리 추가 생성
doc = {
'name': ['세종'],
'age': [23]
}
# pandas에서 append가 추후에 사라지고 concat이 대체할꺼라고 해서 진행해 봄
# df = pd.concat([df, df2])
# ignore_index 인덱스를 직접 안 넣고 자동으로 따라가겠다
df = df.append(doc, ignore_index=True)※ append 함수가 추후 사용 할 수 없게 될 수도 있는데 그때는 concat함수로 대체
표에 열(▼) 추가하기
저장하고 있는 변수(배열)에 열이름 선언(여기서는 ['city']를 입력)
df['city'] = ['서울','부산','서울','부산','부산']
df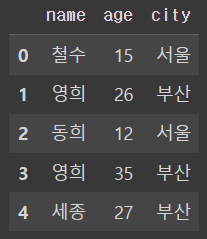
특정 열 & 특정 조건 & 특정 행만 뽑아보기
# 특정 행 - iloc를 사용하여 출력( -1: 맨 마지막 데이터 0: 첫번째 데이터)
df.iloc[-1,0] # 마지막 행
df.iloc[0,0] # 첫 행
# 특정 조건 - 변수에 조건을 미리 입력하여 추후에 출력때 입력
cond = df['age'] < 20 # age가 20 미만인 데이터 출력
df[cond]
# 특정 열만 뽑기 - 해당 열이름만 입력
df[['name','city']] # name, city열만 출력정렬하기 & 조건에 맞는 열 추가 & 평균, 최대값, 최소값, 갯수 구하기
sort_values: 정렬하기
아래에서 age를 축으로 정렬한다.
# sort_values 정렬할때 by = '축- 어디 중심 '
df.sort_values(by='age', ascending=False).iloc[0,1]조건에 맞는 열 추가
np.where: 조건에 맞는 데이터 출력
# df['is_adult'] 열 추가
# np.where로 age가 20 미만이면(True) 청소년,아니면(False) 성인으로 값을 입력
df['is_adult'] = np.where(df['age'] < 20, '청소년','성인')평균, 최대값, 최소값, 갯수
df['age'].mean() # 평균
df['age'].max() # 최대
df['age'].min() # 최소
df['age'].count() # 개수
# describe : 개수, 평균, 표준편차, 최소~최대 등 출력
df['age'].describe()종목 데이터를 가지고 여러 주식 정보를 출력보았어요.
# 종목데이터.xlsx 파일 읽어오기
df = pd.read_excel('종목데이터.xlsx')
# df.head() 위에서 5줄
#df.tail() 밑에서 5줄
df.tail(10) # 밑에서 10줄
# change_rate 어제보다 오늘이 얼마나 올랐냐
cond = df['change_rate'] > 0
df = df[cond] #.head()
# per: 주가를 주당 순이익으로 나눈 것
cond = df['per'] > 0
df = df[cond]
df
# 주당 순이익(eps)
# per = 시가총액/ 순이익 = 주가/ 주당순이익
# 주가 = per * eps
df['close'] = df['per']*df['eps']
df['earning'] = df['marketcap'] / df['per']
df
# del 열 하나 없애기
del df['date']
cond = (df['pbr'] < 1) & (df['marketcap'] > 1000000000000) & (df['per'] < 20)
df = df[cond]
# df.sort_values(by = 'marketcap', ascending= False)
# 평균,최대,최소,표준 등 출력
df[cond].describe()
'스파르타 국비지원 교육 > 스파르타_주식 데이터를 활용한 파이썬 데이터분석' 카테고리의 다른 글
| [내일배움카드 코딩] 5주차_주식 데이터 분석 파이썬 후기 (0) | 2023.06.04 |
|---|---|
| [내일배움카드 코딩] 4주차_주식 데이터 분석 파이썬 (0) | 2023.06.04 |
| [내일배움카드 코딩] 3주차_주식 데이터 분석 파이썬 (0) | 2023.06.04 |
| [내일배움카드 코딩] 1주차_주식 데이터 분석 파이썬 (0) | 2023.05.03 |




